在 Rime 拼音方案中输入英文
用 easy_en 方案挂载到自己的主输入方案(全拼、双拼、五笔等),就可以同时输入英文单词。
我用的是 melt_eng 方案,差不多,就是拼写规则的大小写方面改了一点。
引入示例:
schema:
dependencies:
- melt_eng
engine:
translators:
- table_translator@melt_eng
melt_eng:
dictionary: melt_eng
这样挂载了英文方案与英文词库,在拼音方案下就可以输入英文单词。
因为不是同一个翻译器,英文不会和拼音共同造词,比如输入「applediannao」,并不会自动生成「Apple电脑」,只能给常用的中英混合词汇单独弄一个词典。
期望的行为:
- 拼音优先
输入「ma」,前几个候选项应为「吗 嘛 马」,而不是「Mac mad man」。
- 重码时拼音优先
如「四则」与 size 冲突时,希望「四则」排在第一位
- 短单词优先
输入 mac,第一候选项应为 Mac,而不是「马车」。
可以降低个别短单词在候选项的位置,在下文。
- 未输入完全时的英文长单词:
输入 googl,第一候选项应为 Google,而不是「个哦讴歌来」这种无意义的内容。
目前的问题:
目前的问题是这样的,输入完整的短单词权重低,输入不完整的长单词时第一候选项总是一个莫名其妙的中文。

权重设定
经过多次尝试,最后是给拼音和英文都设置一个权重来搞定的:
# 拼音
translator:
dictionary: rime_ice
initial_quality: x
# 英文
melt_eng:
dictionary: melt_eng
initial_quality: y
尝试过「不设置:-1」「不设置:0」「不设置:1」「1:0」「2:1」「3:2」「2:1.x」。。。
最后发现一个神奇的比例是 2 > x > y > 1。
使用了 1.2:1.1,各方面都比较合适,有点玄学😂。

重码问题
比如 can you she he size man,既是完整拼音,也是完整单词,在输入过该单词后,会有这样的问题:

如果不希望这样,可以直接在词库删掉重码的单词,或永远不输入这个单词,或手动 Fn+Shift+Del 降低权重。
但推荐直接在配置文件中禁用用户词典,因为英文方案不需要造词,自然也就不需要记录到用户词典;没有用户词典,就没有调频。
禁用用户词典还有一个小优点,例如写了这样的固定顺序:
macOS macOS 999
macOS Sierra macOS 1
macOS High Sierra macOS 2
macOS Mojave macOS 3
macOS Catalina macOS 4
macOS Big Sur macOS 5
macOS Monterey macOS 6
macOS Ventura macOS 7
macOS Sonoma macOS 8
那么输入 macos 后,候选项将始终是 macOS 排在第一,接着是最新的系统 macOS Sonoma、macOS Ventura ……
完整的参考配置
参考配置仓库:iDvel/rime-ice
# rime_ice.schema.yaml
# 自定义短语
custom_phrase:
dictionary: ""
user_dict: custom_phrase
db_class: stabledb
enable_completion: false
enable_sentence: false
initial_quality: 99 # 自定义短语给予高权重
# 拼音翻译器
translator:
dictionary: rime_ice
initial_quality: 1.2 # 拼音权重 1.2
# 英文翻译器
melt_eng:
dictionary: melt_eng
enable_sentence: false # 禁止造句
enable_user_dict: false # 禁用用户词典
initial_quality: 1.1 # 英文权重 1.1
comment_format: # 自定义提示码
- xform/.*// # 清空提示码(就是没有那个小尾巴)
解决副作用
日期时间
拼音的 initial_quality 大于 1 后,日期时间的 Lua 脚本 yield 的候选项会跑到最后面,输入 rq/sj 或 date/time 后,候选项处于最末端,date/time 还好,rq/sj 需要翻好多页。解决方法是在 yield() 前设置一个高权重:
- yield(Candidate("date", seg.start, seg._end, os.date("%Y-%m-%d"), ""))
+ local cand = Candidate("date", seg.start, seg._end, os.date("%Y-%m-%d"), "")
+ cand.quality = 100
+ yield(cand)
v 模式
英文的 initial_quality 大于 1 后,方案中的「v 模式」的候选项也跑到最后面了,输入「va」的候选项是「van vain …」,而不是「ā á ǎ à …」,可以通过 Lua 脚本解决。
短单词置顶的问题
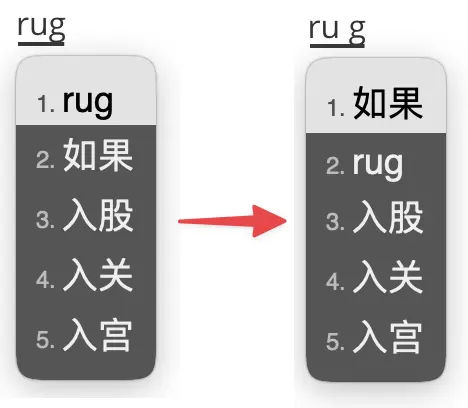
一般输入 Mac 时,可能确实想输入这个单词,那么它在第一个候选项就没问题。
但是输入 rug 这种冷门单词时,用户大概率是想输入「如果」。
这种词汇并不多,日常使用也碰不到几个,可以手动处理。
用 Lua 解决了这个问题。(不会 Lua,感谢大佬 @Shewer Lu 指点)
然后在方案文件 xxx.schema.yaml 中可以配置:
# 增加一个 lua_filter
engine:
filters:
- lua_filter@*reduce_english_filter
reduce_english_filter:
idx: 2 # 降低到第 idx 个位置
words: [rug, bus, ship] # 要降低的单词
效果:
自动大写
由 autocap_filter.lua 实现,感谢 @abcdefg233 @mirtlecn 的几个 PR。
目前雾凇拼音用的是 20k 小词库,只是方便打一些常见英文,并且纯手动调整了一些大小写。
一般情况输入小写即可得到普通单词的小写形式,和大多数人名、地名、专有名词的大写形式。
通过 autocap_filter.lua 可以再将结果进行大写转换,目前的的行为:
| 说明 | code | text |
|---|---|---|
| 输入小写,得到词库中的原样 | latex | LaTeX |
| 输入首字母大写,得到首字母大写 | Hello | Hello |
| 输入前2~n个字母大写,得到全大写 | HEllo | HELLO |
| 同上,输入全大写,得到全大写 | HELLO | HELLO |
拼写派生
在 melt_eng.schema.yaml 中修改了大量派生规则,感谢 @mirtlecn 的 PR(#326)。
派生了一些单词的拼写,对于数字同时支持了英文、全拼及双拼的拼音,也支持了部分符号标点:
| 单词 | 支持的输入方式 |
|---|---|
| i18n | ishiban | ieighteenn |
| K8s | kbas | keights |
| .NET | dotnet |
| Windows 11 | windowsshiyi | windowseleven |
| Windows 2000 | windowsliangqian | windowserqian windowstwoooo | windowserooo |
| D&D | dandd |
对于中英混输词库,所有词条的编码加上了一个特殊符号前缀,防止英文方案拼写派生时派生出全大写字母:
T恤 ⓘTxu
示例:输入 txu 得到「T恤」;输入 Txu 得到「T恤」; 输入 TXU 则只会得到 TXU。