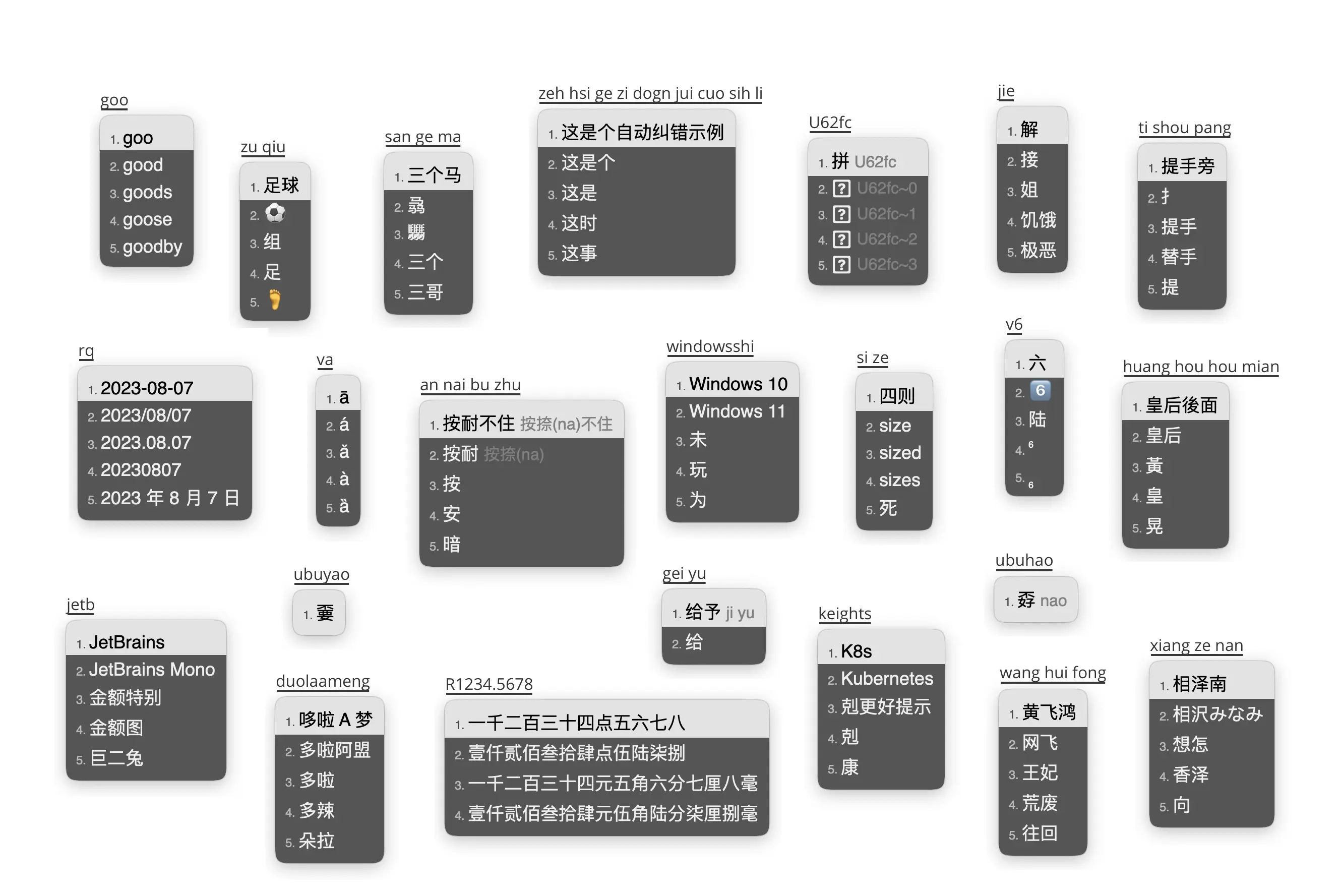
雾凇拼音,功能齐全,词库体验良好,长期更新修订,仓库:iDvel/rime-ice
Rime Input Method Engine / 中州韵输入法引擎 是一个跨平台的输入法算法框架。
基于这一框架,Rime 开发者与其他开源社区的参与者在多个平台上创造了不同的输入法前端实现。
雾凇拼音是 Rime 的一份配置仓库,用户需要下载 各平台对应的前端,并将此配置应用到配置目录。
雾凇拼音提供了一套开箱即用的完整配置,包含输入方案(全拼、常见双拼)、长期维护的开源词库及各项扩展功能。
基本套路
- 简体 | 全拼 | 双拼
- 主要功能
- 轻量的英文输入,支持中英混输
- 优化英文输入体验
- 拆字反查(uU+拼音),拆字辅码(拼音+`+拆字辅码)
- 自整理的 Emoji
- 以词定字(左右中括号:[、])
- 长词优先
- Unicode(U+Unicode 码位)
- 数字、人民币大写(R+数字)
- 日期、时间、星期(详见方案
/date_translator节点) - 农历(转写:N+八位数字;获取当前农历:全拼nl,双拼lunar)
- 简易计算器(cC+算式)
- UUID(uuid)
- 常见错音错字提示
- 置顶候选项(详见方案
/pin_cand_filter节点) - 所有标点符号直接上屏
- 特殊符号、字符输入(全拼v+首字母缩写;双拼V+首字母缩写)
- 拼音纠错(模糊音)
- 更多默认未启用的功能请参考
lua/及方案注释
- 简体字表、词库
- 词库修订
- 校对大量异形词、错别字、错误注音
- 全词库完成注音
- 同义多音字注音
- 参考
- 《现代汉语词典》
- 《同义词词林》
- 《新华成语大词典》
- 校对标准论坛
- Rime、Squirrel、Weasel 常用配置项的详尽注释
方案设计
.
├── default.yaml # 一些全局设置
├── rime_ice.schema.yaml # 全拼方案
├── double_pinyin*.yaml # 双拼方案
├── rime_ice.dict.yaml # 挂载词库
├── cn_dicts/ # 词库目录
├── melt_eng.schema.yaml # 英文方案,作为次翻译器挂载到拼音方案
├── melt_eng.dict.yaml # 挂载词库
├── en_dicts/ # 词库目录
├── radical_pinyin.schema.yaml # 部件拆字方案,作为反查挂载到拼音方案
├── radical_pinyin.dict.yaml # 部件拆字词库
├── custom_phrase.txt # 自定义短语
├── symbols_v.yaml # 全拼 v 模式
├── symbols_caps_v.yaml # 双拼 V 模式
├── opencc/ # 词语映射,Emoji
├── lua/ # 各个 Lua 脚本
├── squirrel.yaml # 鼠须管的前端配置文件
└── weasel.yaml # 小狼毫的前端配置文件
支持了全拼和部分双拼。
对于英文输入做了一些 hack,详见优化英文输入体验。
启用了自定义短语,全拼为 custom_phrase.txt,双拼为 custom_phrase_double.txt 需要手动创建。
将 Rime 默认的「/」模式改为了「v」模式,全拼为小写 v 开头,双拼为大写 V 开头,分别在 symbols_v.yaml 和 symbols_caps_v.yaml 中定义。
支持了 Emoji 和部分词语映射,在 opencc/ 文件夹中定义。
Lua 设置:
提取了一些可配置的选项出来,触发关键字及前缀都可以直接在方案里修改,不用修改 .lua 文件。
以词定字:的快捷键写在了 default.yaml,因为可能和方括号翻页冲突,其余的 Lua 都在方案文件中设定,参考注释即可。
长词优先(全拼):默认是提升 2 个词提到第 4 个位置。
以词定字:默认快捷键为左右中括号 [ ],分别取第一个和最后一个字。
日期时间:全拼的触发编码为 rq sj xq dt ts,双拼为 date time week datetime timestamp。
农历:全拼 nl,双拼 lunar。
在 lua/ 中还有一些默认未启用的脚本,可自行配置。
一些前缀功能的默认设置:
-
symbols:全拼
v开头、双拼大写V开头 -
部件拆字的反查:
uU开头,反查时前缀会消失影响打英文所以设定为两个字母,或可改成一个非字母符号。 -
部件拆字的辅码:
`触发。 -
计算机:
cC开头,前缀会消失影响打英文所以设定为两个字母,或可改成一个非字母符号。 -
Unicode:大写
U开头,如U62fc得到「拼」。 -
数字、金额大写:大写
R开头,如R1234得到「一千二百三十四、壹仟贰佰叁拾肆元整」。 -
农历指定日期:大写
N开头,如N20240210得到「二〇二四年正月初一」。
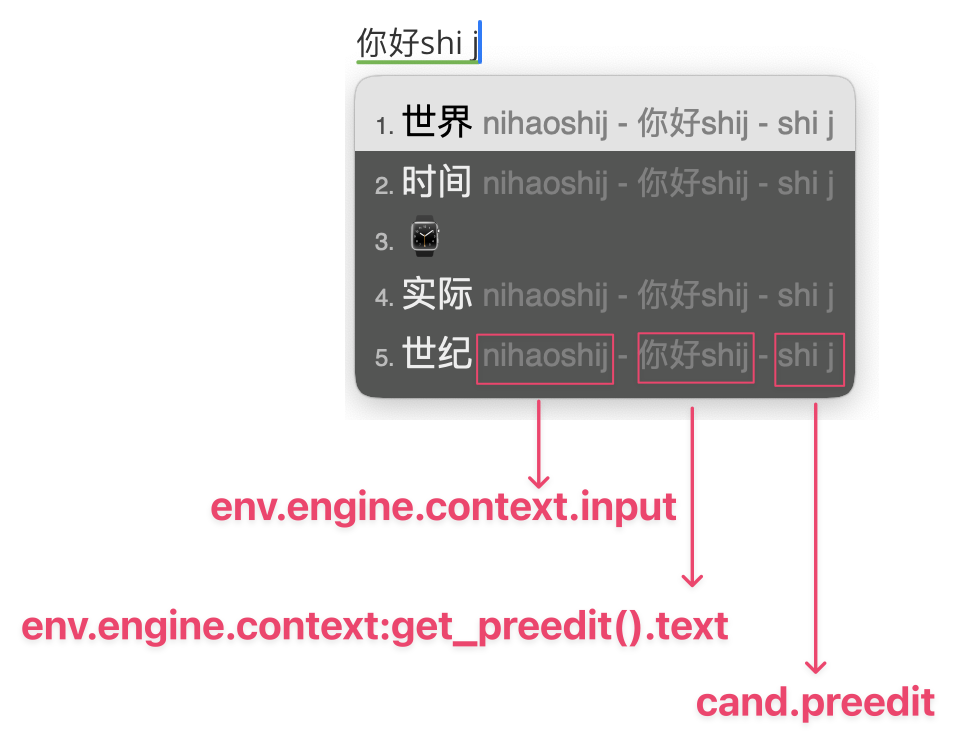
置顶候选项:
自定义短语 custom_phrase 实现置顶是以一个新的高权重的 table_translator 诞生一个新的词汇。
如果在 custom_phrase 里写了 的 de,输入 de 时「的」排在了候选项最前面,接着经过去重,拼音翻译器自己的「的」没了,只保留了 custom_phrase 的「的」。
由于两个翻译器之间无法造词,所以「的」这个字失去了造词效果,因此之前建议只写非完整拼音的编码,如 的 d。
现在由 pin_cand_filter.lua 实现置顶,这个 Lua 仅仅是调整候选项的顺序(没有创造词汇编码的功能),被置顶的「的」仍然是拼音翻译器自己的「的」,可以造词,也就可以置顶完整的拼音。
此功能通过对比去掉空格后的 cand.preedit 来实现,编码一致时,按顺序置顶配置中的词汇;
并与 env.engine.context:get_preedit().text 的字母部分做对比来实现在句子中时仍然置顶。
上手修改
简单来说,default.yaml 是入口文件,决定了一份配置使用哪些方案,可以只保留自己需要的方案。
里面还有一些特殊设定,候选词个数、方案选单、中西文切换等等,另外将一些所有方案较为通用的配置项也写在 default 里了,再在方案中引用。
方案文件 rime_ice.schema.yaml(全拼)或 double_pinyin*.yaml(双拼)是最主要的配置文件,所有功能的引用和实现都在方案文件中。
自定义短语、opencc、symbols 等等是引用的哪个文件、启用了什么 Lua 等等,都是在方案文件中体现的。
melt_eng 与 radical_pinyin 没有作为单独的输入方案,而是作为辅助功能挂载到拼音方案中,以支持在拼音方案下输入英文和拼字。
因为中英文的词库文件较多,rime_ice.dict.yaml 与 melt_eng.dict.yaml 也是作为入口文件,将具体词库放到了文件夹中,让配置目录清爽一些。
无论您是折腾能手还是只想一键使用,都建议至少大概翻看一下 default.yaml 和所使用的方案文件,可以了解到所有功能。
配置中基本都写了注释,大多数修改都非常简单,如候选项个数、各种触发关键字等等,如果只做小修改,通读一遍即可。
尝试折腾期间,直接在现有文件上修改比较方便。若要考虑拉取更新导致的覆盖问题,可参考下文的打补丁方式。
长期维护词库
因为没有找到一份比较好的词库,干脆自己维护一个。综合了几个不错的词库,精心调教了很多。
词库简介:
- 字表:
8105常用字表,《通用规范汉字表》+基本的扩充。41448Unihan 大字表,默认未启用。
- 词库:
base基础词库,含两字词及调频。ext扩展词库,小词库,含多音字注音。tencent扩展词库,大词库,无注音(由 Rime 自动注音),含非多音字、只发一种音的多音字、同义多音字。
- 纯手搓的 Emoji
- 英文词库:
en20k 左右的常见单词 + 少许补充。en_ext扩展词库,大部分是缩写或互联网相关。
维护内容主要是异形词、错别字的校对,错误注音的修正,缺失的常用词汇的增添,词频的调整。
欢迎在词库方面提 issue #666 ,我会及时更新修正。
词库的设计
Rime 自带的「朙月拼音·简化字」方案其实是繁体词库加上一个自动繁转简的设定,出词仍旧是经过 OpenCC 转换,用户词典中保存的输入历史还是繁体的。
简体用户推荐使用简体词库,引入一些第三方词库也比较方便,还可以避免 OpenCC 的少数转换错误,修订词汇时也只需要按照大陆简体标准修订。
多音字
已经为全词库完成注音。
tencent 词库包含的多音字过于庞大,对于没有编码的词库文件,Rime 会根据方案的字表进行自动注音。
当含有多音字的词组缺少编码字段时,自动注音程序会利用权重百分比高于 5% 的读音进行组合、生成全部可能的注音。—— Rime 输入方案设计书
如果不做处理,多音字可以被多种注音打出来,有一些会造成困扰,比如「没发展」可以被 mo fa zhan(魔法战)打出来。
目前的解决方案:
保证 tencent 词库只被一种音注音,手动注音其他音。
例如「的 de di」,手动注音包含 di 音的所有词汇,然后确保字表权重 de * 0.05 > di;
对于「长 chang zhang」这样不易区分的,全部注音并用勤劳的双手完成校对。
tencent 词库还保留了一些同义多音字、文白异读的「血、熟、爪、薄」等等将会自动进行多种注音。
两字词
两字词统一放到 base.dict.yaml 中,便于平时修订和调频。
因为两字词的排序基本决定了词库舒适度,重码较多,所以都加上注音和权重,并大量增删和调频。
扩展词库的两字词都没有自动加入,平时扩充时都是肉眼检查后再添加。
扩展词库
主词库缺少了很多常用词和流行小短句,挂载扩展词库后体验会好很多。
tencent.dict.yaml 只取了腾讯词向量的一百万个词条,算是比较平衡的选择。
base.dict.yaml、ext.dict.yaml 与 tencent.dict.yaml 已经遭受过大量交叉修改,目前的区别就是 ext 里可能包含需要明确注音的多音字,base 里可能包含需要明确调频的同音词。
新手指引
一些桌面发行版:
-
鼠须管 Squirrel —— 官方 macOS 发行版
-
fcitx5-macos —— 小企鹅 Mac 版,支持全局状态和卷轴模式
-
小狼毫 Weasel —— 官方 Windows 发行版
-
Linux 下有 ibus-rime、fcitx-rime、fcitx5,不太了解。
一些参考、文档、教程:
配置中并没有列出属性的所有可选项,有特殊需求可以看看文档。
如果要折腾配置,建议将 官方 wiki 和 方案制作详解 下载下来放在一起,需要查找一些配置项的时候,全局搜索一下即可。
还有很多,已经很全面了,下面的只是结合本配置随便写一点。
字体
推荐霞鹜文楷,它能识别简体的「𰻝𰻝面 biang biang mian」中的「𰻝」😄,而且拿它做 Rime 的字体也不错。
如果要用大字表,候选项中可能充满问号,推荐参考 issues#841 的推荐字体。
目录
-
配置目录 / 用户文件夹:
-
鼠须管:
~/Library/Rime -
小狼毫:
%APPDATA%\Rime
-
-
共享目录 / 程序文件夹:
- 鼠须管:
/Library/Input Methods/Squirrel.app/Contents/SharedSupport - 小狼毫:
<安装目录>\data
- 鼠须管:
自己的配置放到配置目录里就可以。共享目录提供了一些自带的方案及各项默认配置,可以直接引用;无特殊需求,不要修改共享目录的文件。
比如 OpenCC 简繁转换的配置可以直接书写 s2t.json,因为共享目录里已经有相关文件了。
Tab 与空格
注意编辑器的缩进配置。
Rime 的 YAML 配置文件需要严格的缩进,使用两个空格缩进,不要用 Tab。
词库文件的词条是用 Tab 分割的:
拼音 pin yin 1234
拼音<Tab>pin<Space>yin<Tab>1234
对于普通用户来说,推荐使用 VSCode 这种能配置和区分空格与 Tab 的编辑器(而不是记事本),同时使用等宽字体。
其他杂项小说明
完成部署后,首先在 default.yaml 中查看呼出方案选单的快捷键。
build/ 目录是部署后自动生成的,不要修改,出错时可以看看里面生成的是否正确。
首次部署较慢,主要是拼音方案词库很大,如果下次部署前没有修改词库,就会很快完成部署。
translator/enable_user_dict 是默认开启的,即记录用户输入内容。
用户词典类型 translator/db_class 的值默认为 userdb,即二进制文件,输入过的内容会记录在 *.userdb/ 文件夹中,只有在同步后才能在同步目录看到人类可读的用户词典;另一个值是 tabledb,会直接在配置目录生成一个人类可读的 txt 文件。如有多平台同步需求,使用默认值 userdb。
配置的引用
Rime 的配置可以很灵活复杂,比如设置一个快捷键:
- 可以在方案文件
xxx.schema.yaml中设定; - 也可以在方案的补丁文件
xxx.custom.yaml中设定; - 也可以写在
default.yaml或defaut.custom.yaml中,再在方案中引用; - 也可以额外创建一个 YAML 文件,再在方案中中引用。
比如我想让所有方案共用同一套快捷键,不用写很多份。写在 default 中就比较合适,然后再在多个方案中进行引用:
# 1. 在 default.yaml 或 default.custom.yaml 中配置
key_binder:
bindings:
# ... 相关快捷键配置
##############################
# 2. 在多个方案 xxx.schema.yaml 或 xxx.custom.yaml 中引用
key_binder:
import_preset: default # 从 default 继承快捷键的相关配置
import_preset 是导入成套的配置。
__include 是在当前位置包含另一 YAML 节点的内容。
具体用法参考官方 wiki。
下面是一个典型的示例:
# 方案文件 xxx.schema.yaml
punctuator:
# 可以用以下任何方式搞定:
# __include: punctuation:/ # 从共享目录引入预设的 punctuation.yaml
# import_preset: symbols # 从共享目录引入预设的 symbols.yaml
full_shape:
__include: default:/punctuator/full_shape # 从 default.yaml 导入配置
half_shape:
__include: default:/punctuator/half_shape # 从 default.yaml 导入配置
symbols:
__include: symbols_v:/symbols # 从 symbols_v.yaml 导入配置
# 也可以直接在这里配置:
# full_shape:
# ...
# half_shape:
# ...
# symbols:
# ...
以 patch 的方式打补丁
文件名为 xxx.custom.yaml,内容以 patch: 开头的,是补丁文件,注意缩进,可以对原配置进行覆盖和追加。
- 方案
xxx.schema.yaml的补丁文件是xxx.custom.yaml default.yamlsquirrel.yaml就是把结尾的.yaml改成.custom.yaml
具体语法参考官方 wiki:定製指南
patch:
"一级设定项/二级设定项/三级设定项": 新的设定值
"另一个设定项": 新的设定值
"再一个设定项": 新的设定值
"含列表的设定项/@n": 列表第n个元素新的设定值,从0开始计数
"含列表的设定项/@last": 列表最后一个元素新的设定值
"含列表的设定项/@before 0": 在列表第一个元素之前插入新的设定值(不建议在补靪中使用)
"含列表的设定项/@after last": 在列表最后一个元素之后插入新的设定值(不建议在补靪中使用)
"含列表的设定项/@next": 在列表最后一个元素之后插入新的设定值(不建议在补靪中使用)
"含列表的设定项/+": 与列表合并的设定值(必须为列表)
"含字典的设定项/+": 与字典合并的设定值(必须为字典,注意YAML字典的无序性)
patch 时支持用 / 来分隔节点,打补丁时可以这样写(比如有如下文件 rime_ice.custom.yaml):
patch:
a/b: new_value
c/d/e: new_value
但是非补丁的文件只能展开来写(比如 rime_ice.schema.yaml):
a:
b: value
c:
d:
e: value
几个打补丁的示例
# 以 patch: 开头,后面的内容都需要缩进
patch:
##### 修改单项
# 正确 ✅ 这种方式只覆盖 Shift_L,不影响其他选项
ascii_composer/switch_key/Shift_L: commit_code
# 错误 ❌ 这样导致 switch_key 下将只有 Shift_L 一个选项
ascii_composer/switch_key:
Shift_L: commit_code
##### 如果有较多修改项,可以直接全部复制过来再修改
ascii_composer:
good_old_caps_lock: false
switch_key:
Caps_Lock: commit_code
Shift_L: commit_code
Shift_R: noop
Control_L: noop
Control_R: noop
##### 结尾的 /+ 表示在原基础上追加
# 保留已有的快捷键,追加一个逗号句号翻页
key_binder/bindings/+:
- { when: paging, accept: comma, send: Page_Up }
- { when: has_menu, accept: period, send: Page_Down }
如果选项是数组,比如 switches,得用 switches/@n: 什么的,可读性不好,改多了就乱了,万一原始方案文件更改了顺序就会造成错误,不如全部复制过来再改。
编写词库
由于 Rime 的设计,拼音词库中并不适用非拼音编码:
hello hello
世界 s j
蒙奇·D·路飞 meng qi d lu fei
非拼音编码 asdasdasd
Rime 在部署时会综合词库中所有音节和拼写规则生成一个映射表,如果开启了简拼,过多的英文单词会导致打字时极其卡顿。上面单个的编码也会导致 s、j、d 结尾时无法响应超级简拼。
英文建议放到英文方案,非常规的注音建议放到自定义短语 custom_phrase.txt。
词库默认的列是:
---
name: 词库名
version: "版本号"
sort: by_weight(按权重排序) | original(按码表顺序排序)
columns: # 不写 columns 属性时,默认顺序为:
- text # 词汇
- code # 编码
- weight # 权重
- stem # 造词码(不知道是啥,好像和拼音方案没有关系)
...
你好 ni hao 123
对于没有注音,又想设置权重的词库文件,修改列即可:
---
name: xxx
version: "1"
sort: by_weight
columns:
- text # 词汇
- weight # 权重
...
你好 123
挂载自己的词库
词库文件以 .dict.yaml 结尾。
词库由具体方案指定:
# rime_ice.schema.yaml
translator:
dictionary: rime_ice # 挂载词库文件 rime_ice.dict.yaml
可以把所有词条堆在这个文件,也可以将这个文件作为一个入口,通过 import_tables 再挂载多个词库:
# rime_ice.dict.yaml
---
name: rime_ice
version: "1"
import_tables:
- mydict # 挂载配置目录下的 mydict.dict.yaml
- cn_dicts/mydict2 # 挂载 cn_dicts/ 目录下的 mydict2.dict.yaml
...
# mydict.dict.yaml
---
name: mydict
version: "1"
sort: by_weight
...
你好 ni hao 1
世界 shi jie 1
词库名 xxx.dict.yaml 和词库中的属性 name: xxx 可以不同,但建议设置为一样的。
其他类型的词库,可以通过 一些脚本 或 深蓝词库转换 转为 Rime 格式的。
自定义文本
在 custom_phrase.txt 中可以放置一些特定的词汇与编码,比如输入 vmail 得到自己的邮箱,输入 vphone 得到手机号,输入 vuser 得到用户名等等。
我自己的理解:每个方案都有一个主翻译器,例如拼音;也可以增加一个次翻译器,例如英文;还可以再增加其他的,例如自定义文本。
custom_phrase.txt 文件内的字词会占据最高权重,即排在候选项的最前面。(默认是这样的,但可以通过 initial_quality 调整各个翻译器的权重)
自定义文本不与其他翻译器互相造词,如果使用了完整编码,那么这个字或词将无法参与造词,即自造词无法被记住。
所以建议只固定非完整编码的字词,「的de」应为「的d」,「是shi」应为「是s」,「仙剑xianjian」应为「仙剑xj」。
注意全拼的
a o e也是完整拼写,不宜将a o e的单字写进自定义文本,否则「啊 哦 呃」无法进行造词。
💡 置顶已经由 pin_cand_filter.lua 实现,可参与造词。
同步
installation.yaml 文件在第一次部署后会自动生成,在这里可以编辑当前设备的 ID 和同步目录,如:
# 本机的 ID 标志,默认是一串 UUID
# 生成的文件夹是这个名字,可以改成更好识别的名称
installation_id: "MBP-001"
# 同步的路径,默认是当前配置目录下的 `sync/`
sync_dir: "/file/path/sync"
在你输入过内容后,配置目录下会生成 *.userdb/ 文件夹,里面是二进制的用户词典。
点击「同步用户数据」后,Rime 会和配置目录下的 *.userdb/ 进行双向更新同步,并在同步目录(/file/path/sync/MBP-001)下生成的 *.userdb.txt,里面都是输入过的内容。
同步目录里还有其他一些没用的文件,Rime 额外单向备份了配置目录下的 YAML 和 TXT 文件,但只有根目录的,比如文件夹里的词库、八股文模型、
rime.lua就没有被同步过来。
⚠️ Windows 用户注意 YAML 语法,反斜杠在双引号中转义,在单引号中不转义:
sync_dir: "c:\\file\\path\\sync"
sync_dir: 'c:\file\path\sync'
多设备同步
将所有平台的 sync_dir 设定为同一个目录,比如 iCloud、Dropbox 的目录。
多个设备在这个目录中会生成并列的文件夹,里面是用户词典。

PC-1 里点【同步】,通过网盘同步到 PC-2,PC-2 再点同步,才可以获得 PC-1 输入过的内容。
用户词典迁移
如果之前在用别的方案,如 pinyin_simp 或 luna_pinyin。
- 将之前的
pinyin_simp.userdb.txt或luna_pinyin[_simp].userdb.txt放到同步目录 - 命名为
rime_ice.userdb.txt - 修改文件里面的
#@/db_name为rime_ice - 点击【同步用户数据】后就可以了

如果之前用的是繁体词库,还需要提前做一个简繁转换,注意不要把 Tab 全转为空格了。
简单的方法,比如 Mac 上通过 VSCode 打开 ➡️ 全选 ➡️ 左上角 Code ➡️ 服务 ➡️ 将文本转换为简体中文。
或者用 opencc:
$ opencc -c t2s -i in.txt -o out.txt
开关记忆
方案中有几个开关(switches),比如简繁开关、Emoji 开关、中英标点开关。。。
如果设定了 reset,值为 0 或 1,则默认使用第一个或第二个值,即便使用时修改了,切换程序后还是默认值。
如果想让输入法永远记住,需要取消设置 reset,并在 default.custom.yaml 中写入 save_options。
永远记住的前提是通过方案选单选择,而不是快捷键切换 (╯’-’)╯︵┻━┻
部分前端(如小企鹅),实现了全局状态,切换后在任何焦点都会记住;
部分前端(如鼠须管),仅在当前会话中记住,每个App或一个App的不同输入框都会单独管理;
部分前端(如小狼毫),仅实现了中英全局状态,其他开关仍然是单独管理。
如何删除相关功能
比如删除英文输入,所有的相关配置是这些:
# dependencies 下的:
- melt_eng
# engine/translators 下的:
- table_translator@melt_eng
melt_eng:
dictionary: melt_eng
拼字方案同样,此外还有一些 Lua 的功能,直接在 engine 下注释掉那一行就禁用了。
皮肤
- 鼠须管文档:鼠须管界面配置指南
- 小狼毫文档:Weasel 定制化
在 squirrel[.custom].yaml 或 weasel[.custom].yaml 中配置鼠须管或小狼毫的皮肤,各平台的前端并不一致,鼠须管的皮肤无法用在小狼毫上。
这里有一个鼠须管内置皮肤的展示图:NavisLab/rime-pifu(图片备份),小狼毫自带皮肤预览。
{kind=link}
需要自己设计皮肤的,鼠须管推荐用这个图形化的皮肤设计器,鼠须管主要维护者写的:LEOYoon-Tsaw/Squirrel-Designer
小狼毫的在线设计网页:RIME 西米 (小狼毫主要维护者的)
查看日志
-
【中州韵】
/tmp/rime.ibus.* -
【小狼毫】
%TEMP%\rime.weasel.* -
【鼠须管】
$TMPDIR/rime.squirrel.*
日志级别分为 INFO WARNING ERROR,查看示例:
$ cat $TMPDIR/rime.squirrel.INFO
鼠须管我经常碰到一个小问题,有时候都弹通知报错了,但是日志是空的,根本没有这个文件。可以直接结束鼠须管进程,它自动重启后就好了。
删词 or 降权
可以删除自造词,或降低词库中已有词语的权重(回到原始权重,不是降到最低)。
- 鼠须管使用 Fn + ⇧ + ⌫
- 小狼毫使用 Ctrl/Shift + Del
想永久删除一个词库中存在的词汇,只能编辑词库,重新部署。
如果各位有在使用过程中有发现什么错别字,希望可以提个 issue。
Tab 切光标
这功能挺好用的,每次用别人的电脑打字都会怀念这个功能。
已经默认开启,可以使用 Tab 或 Shift + Tab 在拼音中前后移动。

对于「xian西安」「tian提案」这种拼音,如果想切到「xi、ti」的后面,只能用左右方向键移动。
另外 Shift + ⌫ 可以删除单个汉字的拼音。
不同的上屏方式
按下空格会上屏汉字,按下回车会上屏字母(可临时输入一些词库中没有的英文)。
以输入「虐心 nue’xin」为例:
- 按回车,上屏的是
nuexin。 - 按 Ctrl/Shift + 回车,上屏的是
nve xin。(u → v,中间有空格)
translator/preedit_format 这里会影响输入框和 shift + 回车时的显示,比如是显示 nue、nve 或 nüe。
如果是双拼方案,preedit_format 还可以选择是否在输入框进行转换,比如小鹤双拼输入 zz 时,是显示 zz 还是 zou。
要设置双拼不转换为全拼,可以直接把 preedit_format 及下面那些 xform 都删除,或者这样打补丁:
patch:
translator/preedit_format: []
opencc
opencc 除了做简繁转换,也可以做词语映射。
比如想输入摄氏度的符号 °C ,可以自定义文本 custom_phrase.txt 中写上:
°C sheshidu
但这样,这个符号会顶到第一个候选项,重码时影响平时打汉字。推荐用 opencc 的方法,Emoji 就是这样实现的。
摄氏度 摄氏度 °C
足球 足球 ⚽
输入内容<Tab>响应内容1<Space>响应内容2<Space>响应内容3...
输入 摄氏度,第一个候选项是其本身,后续则是映射的其他内容。类似输入 提手旁 会得到 提手旁 扌,输入 相泽南 会得到 相泽南 相沢みなみ 等等都是这么做的。
这个「输入内容」其本身应该在词库中存在,否则只能输入过一次后才会有响应。
还有个用法是 show_in_comment: true,可以让「响应内容」放到 comment 里面。
show_in_comment: true 可以实现显示英文单词的翻译,类似哈利路亚输入法,尝试过加入这个功能,一是没有找到比较好的简短翻译数据;二是 Rime 的 comment 区域并不是一个独立存在的窗口,翻译和候选项挤在一起看起来乱糟糟的。
东风破
「東風破早梅,向暖一枝開。」
东风破 plum 是 Rime 官方的一个配置管理工具。
下面是一个简单使用示例,可以在任意文件夹下运行(使用前请备份并清空配置目录):
$ git clone --depth=1 https://github.com/rime/plum
$ cd plum
$ bash rime-install iDvel/rime-ice:others/recipes/full
得,这就安装完了雾凇拼音。
全量更新,再用一次 full 配方即可:
$ bash rime-install iDvel/rime-ice:others/recipes/full
单独更新词库可以用另一个配方:
$ bash rime-install iDvel/rime-ice:others/recipes/all_dicts
例如小鹤双拼,可以在首次安装后再自动打一个补丁:
bash rime-install iDvel/rime-ice:others/recipes/config:schema=flypy
可以查看配置仓库中的 *.recipe.yaml 配方文件,来查看这个配方到底更新了什么。